Self-supervised Adaptation for Open Vocabulary Semantic Segmentation via 3D Mapping
Michele Antonazzi, Timon Homberger
Michele Antonazzi, Timon Homberger
In recent years, open-vocabulary semantic segmentation (OVSS) has become extremely popular as it enables a robot to detect objects from textual prompts without requiring a predefined set of class lables. This task is performed by modern visual foundation models (e.g., SED or CATSeg) based on CLIP. Despite their great potential and generalization capabilities, these models are affected by the well-known domain shift when deployed on mobile robots. It occurs when the training and test data distributions differ, causing performance degradation. Sensor noise, varying illumination conditions and small objects with peculiar textures and visual aspects can easily produce ambiguities and misclassifications as they may be underrepresented in common internet-scale datasets used for training contrastive foundational models such as CLIP. Unsupervised domain adaptation is a relevant paradigm as it mitigates domain shift by fine-tuning the model using robot data without relying on ground-truth labels or humans in the loop. Despite promising, these approaches have been rarely applied to OVSS.
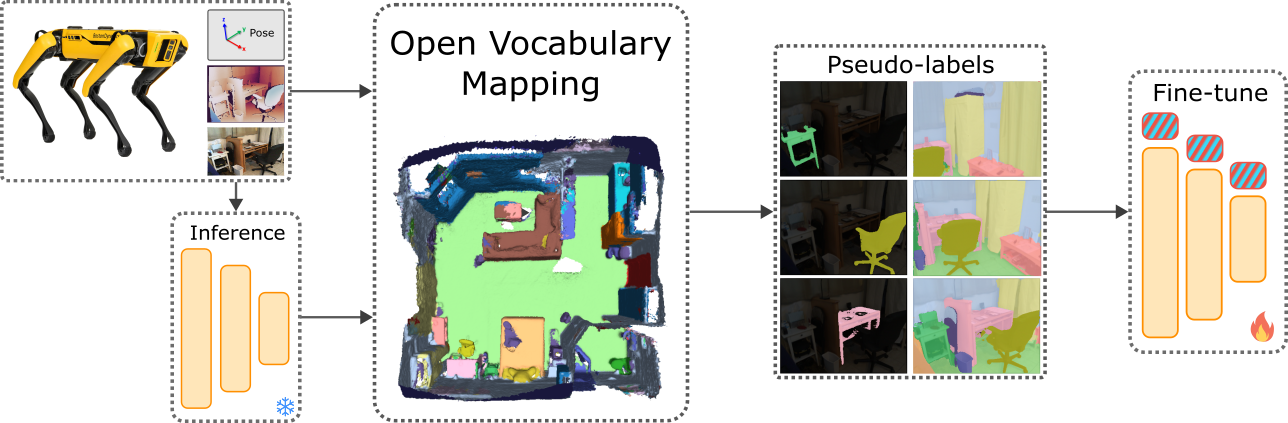
The general overview of the unsupervised domain adaptation pipeline for open-vocabulary semantic segmentation.
The goal of the project is to design, implement, and validate a self-supervised domain adaptation pipeline for OVSS of robotic data (see the figure for a general overview), that can be seen as an extension of this published work. From a stream of robotic perceptions (RGB images and depth data) acquired in an environment, use an open-vocabulary segmentation module to produce self-supervised pseudo-labels. In standard domain adaptation, pseudo-labels refer to labels (i.e., predictions) produced by the model, but in OVSS, they are typically represented as high-dimensional feature vectors. Due to noise and inaccuracies, these pseudo-labels cannot be directly used for self-supervision. To improve their quality, the pseudo-labels can be spatially aggregated using an existing 3D open-vocabulary mapping framework (FUS3DMaps) to obtain an accurate instance-level semantic representation of the environment. The last step consists of querying the map (i.e., back-project 3D views into the image space) to obtain more reliable pseudo-labels to fine-tune the model for performance improvement. The schedule of the activities can be roughly organized as follows (ongoing adjustments are possible):